
Solving the hallucination problem in agents - with loops and math!
What mathematics tells us about loop design in agents

The #1 reason I hear from AI sceptics about why agent-first will not work in the enterprise is that models still hallucinate and “only predict the best next word.” Which is correct but also means nothing! Well, at least it doesn’t mean you cannot solve for that problem. In this article I argue that whether human or math, finding the optimal solution means iteratively looping between attempt and failure until you find a stable optimum.
First of all, humans hallucinate too. It’s not that we take all the information available in and come up with the perfect response every time. We wouldn’t even assume this. Instead: we iterate. We iterate by playing a ping pong of hypothesis, testing, analysing errors, talking to a colleague for a second opinion and then trying again. We also deliberately design test frameworks to mirror that and we spend a decent amount of time reasoning through the optimal shape of the output. So if humans work this way, surely we wouldn’t assume agents are suddenly different?
Second, even in mathematics you would not generally assume that the optimal solution to a complex problem appears on the first try. Optimization is usually iterative. You define what “better” means, generate a candidate, evaluate the error, use that signal to adjust the next candidate, and repeat. Sometimes you follow a gradient. Sometimes you sample broadly. Sometimes you compare competing candidates. But the underlying pattern is the same: progress comes from a loop, not from a single prediction. The relevant question for enterprise agents is therefore not whether the first model output is perfect. It is whether the surrounding system can evaluate it, constrain it, correct it, and improve it over successive steps.
This is the most underestimated insight in agentic platform design. Agents are not deterministic systems that produce the right answer on the first try. They are probabilistic systems that produce a candidate, get evaluated, adjust, and produce another candidate. The first output is almost never the right one. The tenth might be; the fortieth almost certainly is. And that's not because the loop runs long enough by chance, but because each iteration is informed by what the platform learned from the last one.
It’s interesting to see how much people usually great at system design struggle with this, and my feeling is that’s because they are used to designing for deterministic systems and struggle with probabilistic ones. Which is strange because they should be designing systems for humans, which are probabilistic machines in a way too. So the way you design for agents is to design for failure in advance, embrace failure as something helpful that you can use as additional input in the next attempt. Let’s dissect how to do this.
Optimizing for failure
Most enterprises think about AI in terms of model quality. Better model, better answer yet that is almost certainly the wrong approach. A leading model without the platform substrate to fail and iterate from that failure is worse than a mediocre model with a well-structured failure loop.
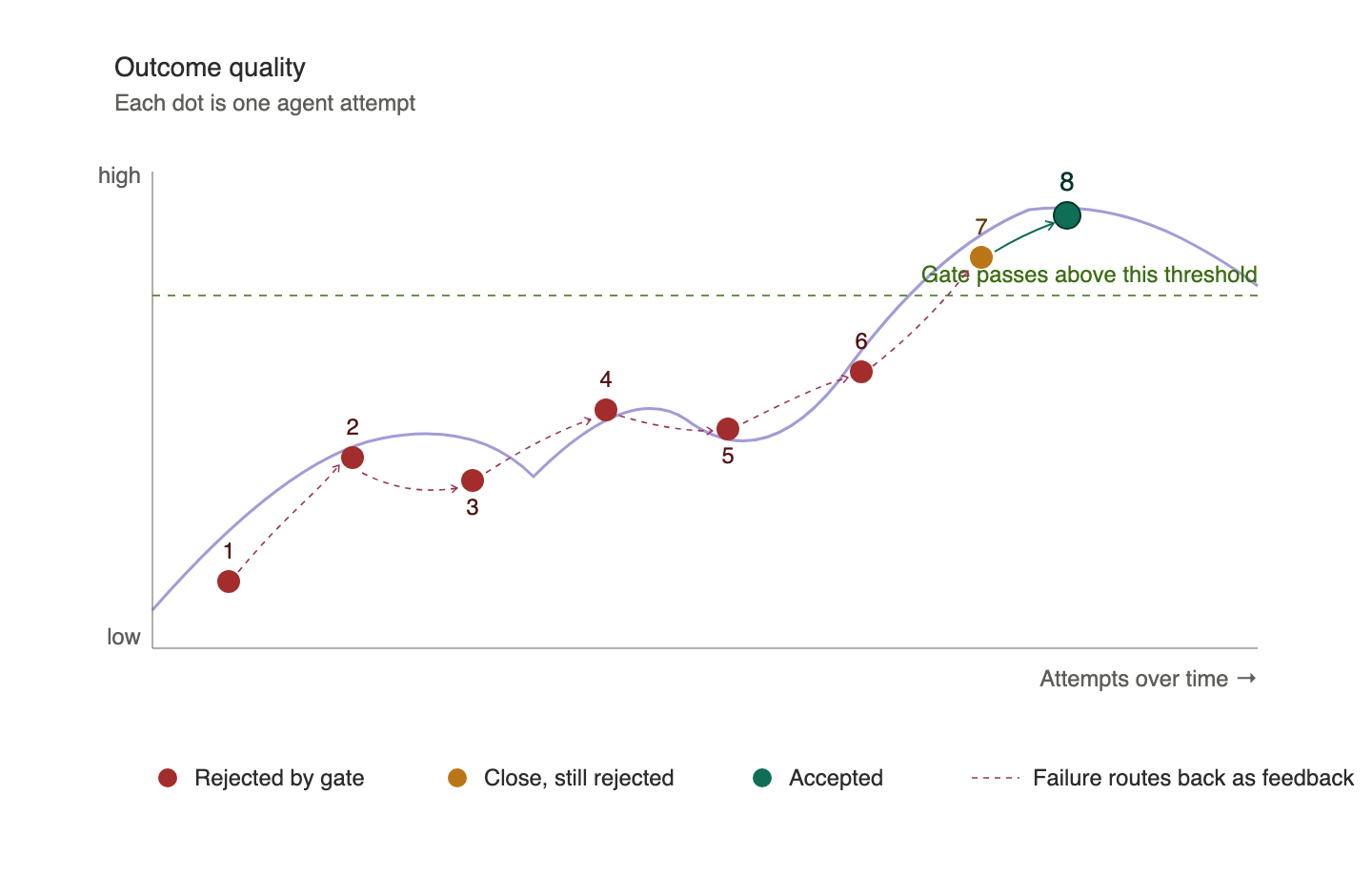
Look at the chart above: each red dot is an agent attempt. The first attempt lands low because a validation gate rejects it. That rejection routes back to the agent as feedback, and the agent tries again. Attempts two through six all fail to clear the threshold, but each one is informed by what came before. Attempt seven gets close. Attempt eight finally crosses the gate, and the output is accepted.
Notice what happens in the middle of the curve. Attempts four and six look like local maxima just because they are better than what came before. A naive system would accept them and move on. But the gate threshold is set higher, because the platform knows that a local maximum is not a global maximum. The loop continues until the system genuinely converges on quality, not just on improvement.
In order to pull this off we need to get three things right:
Defining “done”: a crystal clear definition of what “good enough” means in terms of output.
Evaluating “done”: validation gates that check where we currently stand against that “good enough” output which is essentially a labelling function, and the optimization function the loop runs against every iteration.
Routing efficiently: routing within the platform to have all of those things flow through in sequence as a genuine loop, not a gate the agent walks through once.
Defining “done”
The first thing to get right when going “agentic” is to actually jot down what “done” means.
Ask ten engineers what a “good PR” looks like and you will get ten different answers. Basic tests pass, the code is readable and all the conventions are followed. Valid answers each one, but that information sits mostly in what I’d call tribal knowledge, in the brains of a couple of senior people (in our upcoming book we call these setups “hero-based production systems”). This sort of works for humans because humans are slow, but it absolutely breaks with agents. An agent produces fifty PRs in an afternoon across parallel work streams, and without an explicit definition it has nothing to converge on.
A useful definition of done is composite. It spans functional correctness (tests pass), architectural alignment (matches team conventions), policy compliance (security, licensing, regulatory), and operational characteristics (performance under load). The composition of these into a single verdict is the actual definition of done, and it should be written down and live in a repository.
The software discipline has it easy here because most criteria are hard: code compiles or it does not, the UI renders or it breaks, the policy gate approves or blocks. Decades of CI/CD investment built a vocabulary for measuring this. Other verticals have nothing like it. What does “done” mean for a marketing email sequence? Most teams have no formal answer. The pattern that works is to copy the software world: defined sender identity, expected analytics events, brand compliance checks, deliverability validation. Building this vocabulary for sales, finance, legal, and every other vertical that wants to run agents at scale is enough work for the next decade.
Soft criteria are now in scope too. An LLM-as-judge with a rubric and reference examples can evaluate things deterministic systems cannot: style guide alignment, tone of voice, architectural intent. Noisy, but noise is acceptable when the loop is iterative. And humans stay in the loop where it matters. Not reviewing every diff, but reviewing the small set of candidates the platform deliberately routed to them. I wrote about levels of agentic software development in our last newsletter.
Two things to get right: strictness is a cost lever: loose definitions converge fast and ship low quality, strict definitions converge slowly and burn tokens, too strict and the loop never converges at all. And the definition is versioned, not fixed: you will set the bar wrong on the first attempt, observe and tune, treat it like an SLO.
The teams that get this right look like they have unlocked a productivity miracle. What they have actually done is move from implicit knowledge in the heads of a few to clearly written definitions.
Evaluating “done”
Measuring whether a candidate meets the definition of done is the next problem, and it is where the platform actually earns its keep.
Evaluation in an agentic platform is not a single gate at the end of a pipeline. It is the optimization function the loop runs against, every iteration, from the very first attempt. The candidate comes out of the agent, the platform evaluates it against the definition of done, the verdict either promotes the change or routes the failure back as feedback. The quality of that verdict determines whether the loop converges on real quality or wastes tokens on local maxima.
In practice the evaluation surface is several gates composed together, and the composition is where most of the platform engineering work lives. A healthy balance combines both probabilistic and deterministic gates.
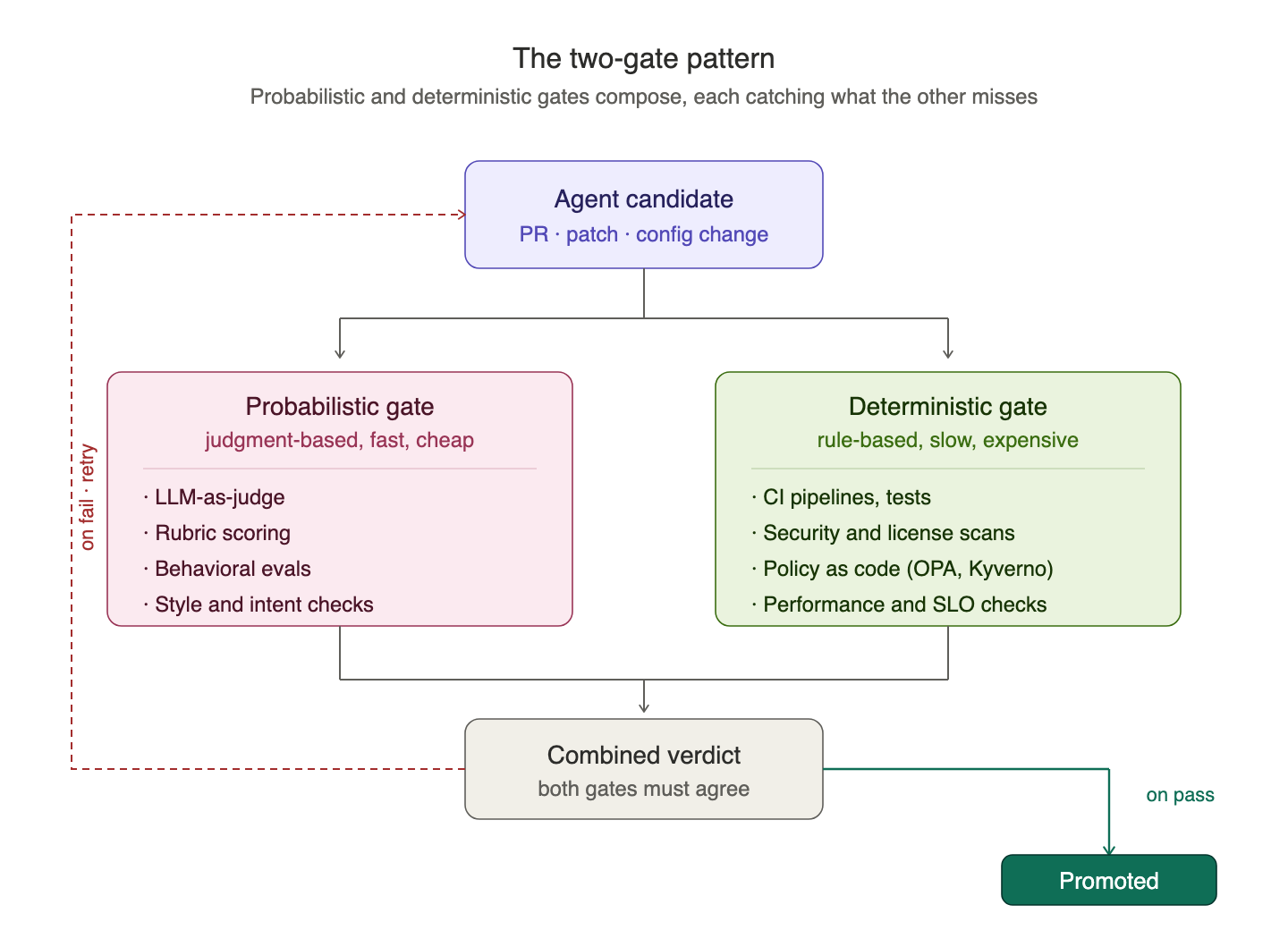
The probabilistic gate runs LLM-as-judge checks, rubric scoring, behavioural evals, and intent verification. It is fast, cheap, and good at the soft criteria. It checks whether the change matches the spirit of the request, whether the code reads cleanly, and whether the agent understood what was actually being asked.
The deterministic gate runs CI pipelines, tests, security scans, and policy as code. It is slower, more expensive, and good at the hard criteria. It checks whether tests pass, the policy is enforced, and the dependency graph is clean.
A probabilistic gate alone produces too many false positives; the deterministic gate alone misses anything that requires judgment. But the composition, run as a loop, catches what otherwise would be missed. In practice the probabilistic gate usually runs first as a cheap filter, and only candidates that clear it get sent to the expensive deterministic checks.
One thing worth naming explicitly: running this loop at agent speed creates real infrastructure pressure that human-paced development never triggered. More pipeline executions, more ephemeral environments, more compute. Validation also needs to widen beyond tests to include security scanning, dependency analysis, and policy checks, because the volume of agent-generated changes makes manual review impossible. That cost is real and has to be planned for.
Humans are the third gate, used sparingly and depending on the level of confidence and the stakes. Some decisions should not be made by automated evaluation, in particular high-blast-radius changes, customer-facing claims, refactors that touch critical paths. For these, the loop runs to convergence against the automated gates, produces a candidate that passes everything the platform can measure, and then routes to a human for the final judgment call. The human is no longer reviewing every diff; instead they are reviewing the small set of candidates the platform deliberately chose to escalate. Used well, this turns the human reviewer into the highest-value, lowest-volume gate in the system.
Two things to get right. Threshold tuning is where most teams fail. Set the gate too low and you ship local maxima. Set it too high and the loop never converges and you burn tokens forever. The only way to find the right setting is to observe the loop in production: attempt counts per accepted output, cost per accepted output, convergence curves over time. Without this observability, you are tuning blind. While deterministic gate output is obvious (you can make certain criteria mandatory and put scoring behind softer factors), probabilistic gates are different. What worked for me is building multiple LLM-based gates, using different models and different context, and letting each suggest a score and when running it you only let it “pass” if it clears a self-defined threshold. This additional layer introduces a certain randomness but in combination with several probabilistic gates works really well.
Eval frameworks are the new test frameworks. Braintrust, Langfuse, LangSmith are doing for probabilistic evaluation what JUnit and pytest did for deterministic testing fifteen years ago. They deserve the same investment. The team that takes evaluation seriously will build their evals like first-class infrastructure, version them, review them, and treat regressions in eval quality the same way they treat regressions in production code.
The mental model shift here is the important one. Evaluation is not a one-shot quality check after the work is done. It is the optimization function the platform runs continuously, essentially the thing the loop converges against.
Routing efficiently
You have defined done and you have built the gates that evaluate it. The last problem is connecting them into a flow that actually converges, at acceptable cost, without producing a chaos of half-finished attempts.
This is the routing problem, and it is where platform engineering shows up most visibly in an agentic system.
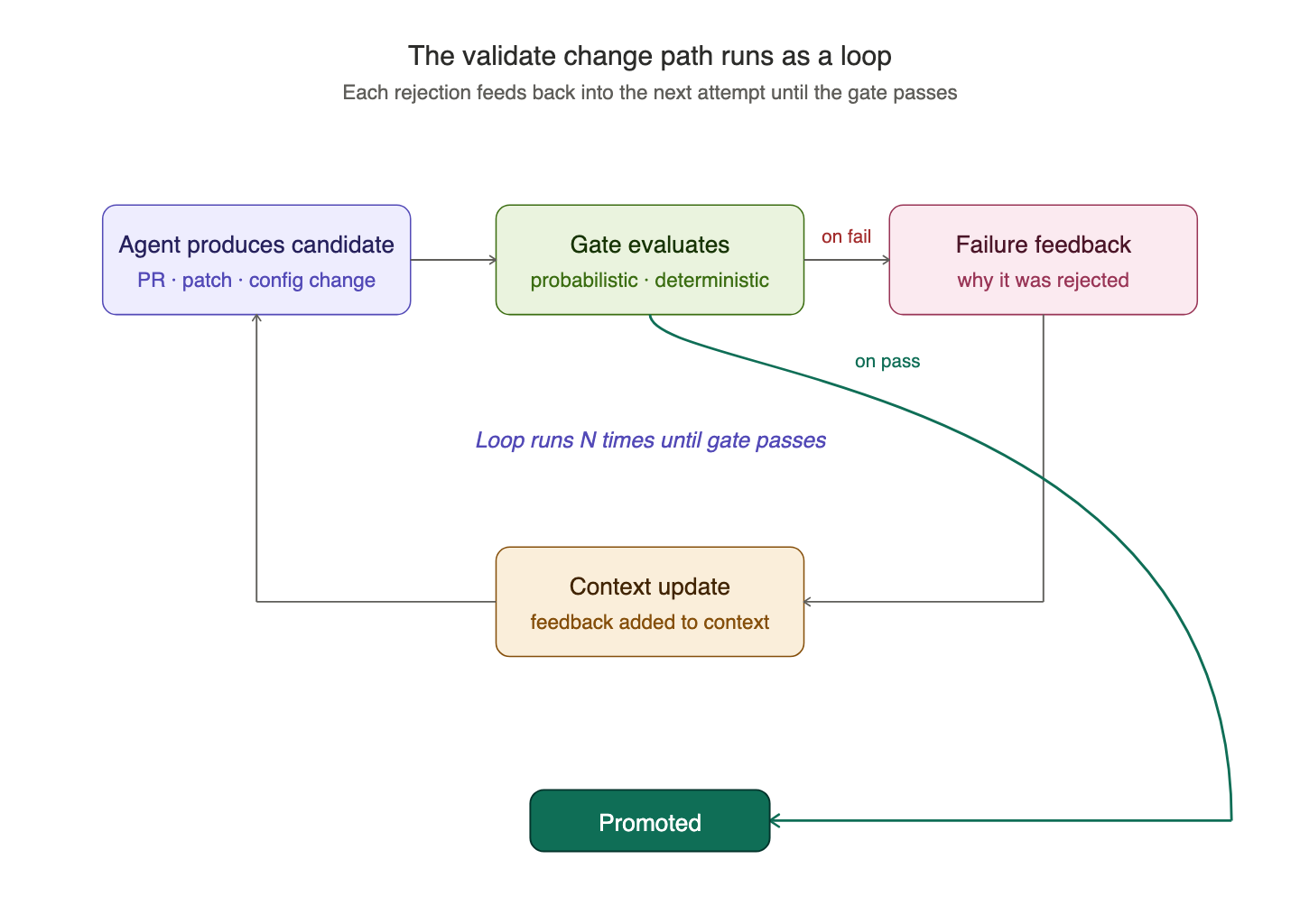
The trick is to design this as a loop: the agent produces a candidate, then the gate evaluates it. On failure, the result becomes feedback and the context updates with that feedback. The agent produces a new candidate. The loop runs N times until the gate passes, at which point the change is promoted out of the loop.
This structural shift is the most underestimated change in agentic platform design. A gate is something a human walks a PR through. A loop is something an agent runs against until it converges.
Three things to get right.
Context update is where most loops fail. Routing the failure signal back to the agent without enriching its context just produces the same failure again. The agent needs to know what was rejected, why, and what the gate would have accepted instead. This is the stage most teams underbuild, because it looks like plumbing. In reality it is the difference between a loop that converges in three attempts and one that runs forty times producing the same wrong answer.
Cost controls are not optional. An agent will happily burn through your budget on a problem it cannot solve. The platform needs hard limits per loop: maximum attempts, maximum cost per candidate, maximum wall-clock time. When the limits are hit, the loop terminates and routes to a human, or backlogs the work with a clear signal that the platform could not converge.
The loop needs to be observable as a loop and doesn’t mean as an individual tool calls or individual model invocations, but as a complete cycle with attempt counts, convergence curves, and cost-per-accepted-output. This is the dashboard platform teams need but most do not have yet. Without it, you cannot tell whether your loop is healthy or whether it is silently degrading.
Closing the loop
Path design is the new platform engineering primitive. The dispatch, the gate, the feedback router, the context updater, the promotion exit, the cost ceiling. Each is a piece of infrastructure that has to be built, owned, and operated. This is the work that separates a platform that scales agentic development from one that produces a chaos of half-finished attempts.
The pattern that runs through all of this is the same one mathematicians have used for centuries and humans use without thinking. You do not solve a hard problem in one shot. You produce a candidate, you check it against what “better” looks like, you use the failure to inform the next attempt, and you keep going until you converge. Agents are no different. The only thing that is different is the speed at which the loop can run, and the scale at which the platform has to govern it. Higher speed and higher autonomy demand more platform maturity — not less. The governance has to grow with the capability, or the loop becomes reckless rather than productive.
So the answer to “agents hallucinate” is not “wait for a better model.” It is “build a platform that loops against failure intelligently.” And in this world the model is the worker and the platform is the production system. Anyone who has spent time in platform engineering will recognise this distinction immediately, because it is the same distinction that separated teams that scaled software delivery in the 2010s from teams that did not.
For platform engineering teams, this is the work of the next decade. Defining done in places where it has never been written down. Building evaluation as first-class infrastructure. Designing paths that route candidates through gates and feedback through context. The teams that get this right will look, from the outside, like they have unlocked something magical. They have not. They have applied the iterative loop — which has always worked — to a new kind of worker that can run it at a speed no human can match.
The sceptics are correct that models hallucinate. They are wrong about what that means. It does not mean agentic development cannot work in the enterprise. It means the enterprises that succeed will be the ones that take failure seriously enough to build a system around it.